Most of us, when conducting OSINT tasks or gathering information for preparing a pentest, draw on Google hacking techniques like site:company.acme filetype:pdf “for internal use only” or something similar to search for potential sensitive information uploaded by mistake. Other times, a customer ask us to know if they have leaked in a negligence this kind of sensitive information and we proceed to make some google hacking fu.
But, what happens if we don’t want to make this queries against Google and, furthermore, follow links from search that could potentially leak referers? Sure we could download documents and review them manually in local but it’s boring and time consuming. Here is where Apache Solr comes into play for processing documents and create index of them to give us almost real time searching capabilities.
What is Solr?
Solr is a schema based (also with dynamics field support) search solution built upon Apache Lucene providing full-text searching capabilities, document processing, REST API to fetch results in various formats like XML or JSON, etc. Solr allows us to process document indexing with multiple options regarding of how to treat text, how to tokenize it, convert (or not) to lowercase automatically, build distributed cluster, automatic duplicates document detection and so.
Setting up Solr
There are a lot of stuff about how to install Solr so i’m not going to cover it, just specific core options for this quick’n dirty solution. First thing to do is creating core config and data dir, in this case i created /opt/solr/pdfosint/ and /opt/solr/pdfosintdata/ to store config and document data respectively.
To set schema up just create /opt/solr/pdfosint/conf/schema.xml file with following content:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
Just a quick review of config for schema.xml, i specified an id field to be unique (UUID), a text field to store text itself, timestamp to be setted to date when document is pushed into Solr, version to track index version (internal Solr use to replicate, and so) and a dynamic field named attr_* to store any no specified value in schema and provided by parser. At last, i specified how to treat indexing and querying, for tokenize i use whitespice (splice words based just on whitespace without caring about special punctuaction) and convert it to lowercase. If you want to know more about text processing i would recommend Python Text Processing with NLTK 2.0 Cookbok as an introduction, Natural Language Processing with Python for a more in-depth usage (both Python based) and Natural Language Processing online course available in Coursera.
Next step is notyfing Solr about new core, just adding to /opt/solr/solr.xml/
1 2 3 4 | |
Now only left to provide Solr with binary document processing capabilities through a request handler, in that case, only for pdfosint core. For this create /opt/solr/pdfosint/solrconfig.xml (we can always copy provided example with Solr and modify when needed) and specify request handler:
1 2 3 4 5 6 7 8 | |
A quick review of this, class could changed depending on version and classes names, fmap.content specify to index extracted text to a field called text, lowernames specify converting to lowercase all processed documents, uprefix specify how to handled field parsed and not provided in schema.xml (in that case use dynamic attribute with a suffix of attr_) and captureAttr to specify indexing parsed attributes into separate fields. To know more about ExtractingRequestHandler here.
Now we have to install required libraries to do binary parsing and indexing, for this, i have created /opt/solr/extract/ and copied solr-cell-4.2.0.jar from dist directory inside of Solr distribution archive and also copied to the same folder everything from contrib/extraction/lib/ again from distribution archive.
At last, adding this line to /opt/solr/pdfosint/solrconfix.xml to specify from where load libraries:
1 2 3 | |
To know more about this process and more recipes, i strongly recommend Apache Solr 4 Cookbook.
Indexing and digging data
Now we have a extracting and indexing handler at http://localhost:8080/solr/pdfosint/update/extract/ so only rest to send PDF to Solr and analyze them. The easyiest way once downloaded (or maybe fetched from a meterpreter session? }:) ) is sending them with curl to Solr:
1
| |
After a while, depending on several factors like machine specs and documents size, we should have an index like this:
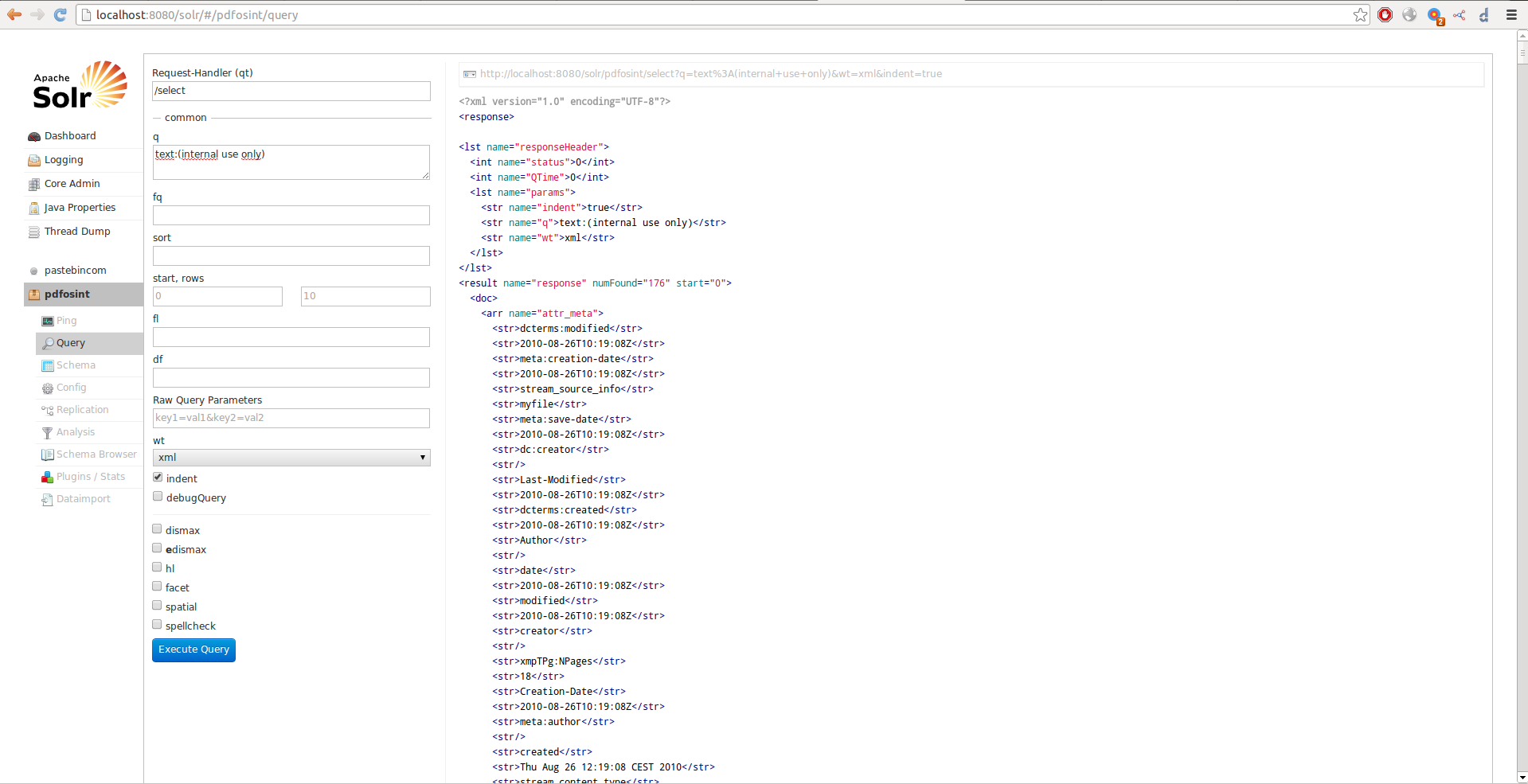
So now we try a query to find documents with phrase “internal use only” and bingo!:
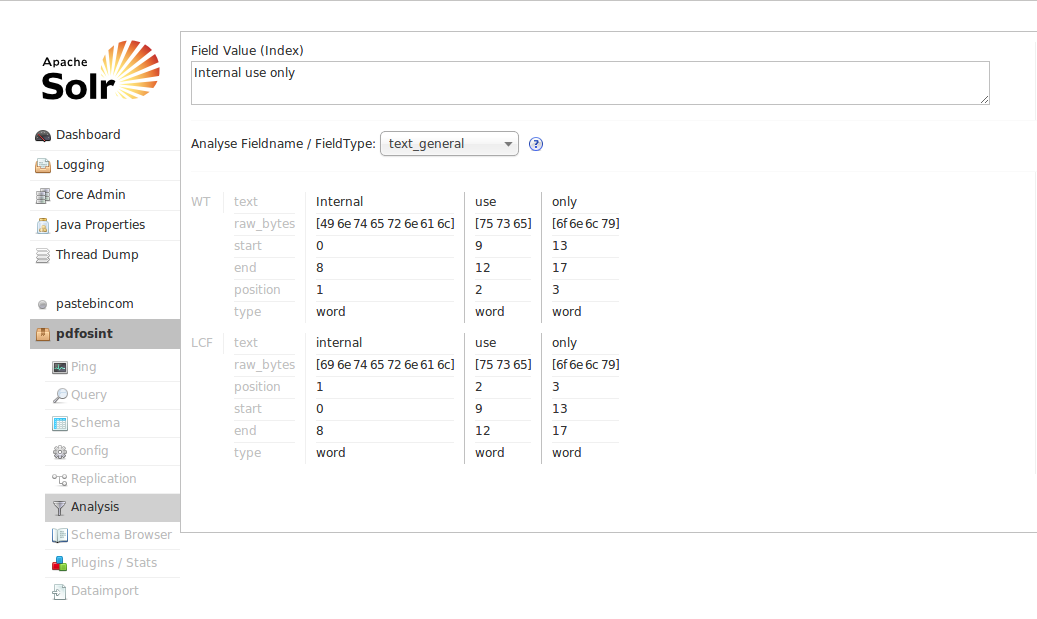
It’s important to have in mind the fact that Solr split words and treat them before indexing when doing queries, to see how a phrase should be treated and indexed by Solr when submitted we can do an analysis with builtin interface:
I hope you find it useful and give it a try, see you soon!