Introduction
As we saw in last post it’s really easy to detect text language using an analysis of stopwords. Another way to detect language, or when syntax rules are not being followed, is using N-Gram-Based text categorization (useful also for identifying the topic of the text and not just language) as William B. Cavnar and John M. Trenkle wrote in 1994 so i decided to mess around a bit and did ngrambased-textcategorizer in python as a proof of concept.
How N-Gram-Based Text Categorization works
To perform N-Gram-Based Text Categorization we need to compute N-grams (with N=1 to 5) for each word - and apostrophes - found in the text, doing something like (being the word “TEXT”):
- bi-grams: _T, TE, EX, XT, T_
- tri-grams: _TE, TEX, EXT, XT_, T_ _
- quad-grams: _TEX, TEXT, EXT_, XT_ _, T_ _ _
When every N-Gram has been computed we just keep top 300 - William and John observed this range as proper for language detection and starting around 300 for subject categorization - and save them as a “text category profile”. For categorize a text we only have to make same steps and calculate the “Out-Of-Place” measure against pre-computed profiles:
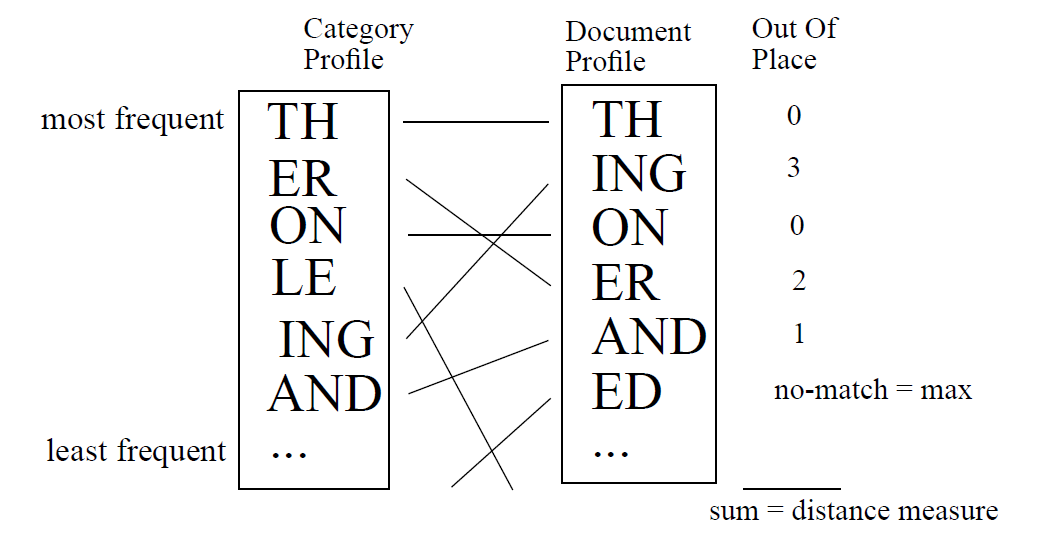
Then, choose the nearest one - the one with lower distance - among them.
Implementing it in python
Procedure to create a text category profile is well explained at point “3.1 Generating N-Gram Frequency Profiles” and it’s really easy to implement it in python with the help of powerful nltk toolkit.
First step: Split text into tokens (tokenization)
We need to tokenize text splitting by strings of only letters and apostrophes so we could use nltk RegexpTokenizer for this:
1 2 3 4 | |
It’s just a proof of concept and should be tuned, but will be enough for now.
Second step: Generating N-grams for each token
Now it’s time to generate n-grams (with N=1 to 5) using blank as padding, again nltk has a function for it:
1 2 3 4 | |
ngram function will return a tuple so we need to join positions in ngrams itself:
1 2 | |
Third step: Hashing into a table and countig each N-gram occurrences
The easiest way to do this is using a python dictionary, doing a sum when ngram has been seen before or creating a new key otherwise:
1 2 3 4 5 6 7 8 | |
Fourth step: Sort in reverse order by number of occurrences
By last, we need to sort previously created dictionary in reverse order based on each ngram occurrences to keep just top 300 most repeated ngrams. Python dict’s can’t be sorted, so we need to transform it to a sorted list, we can easily achieve it using operator module:
1 2 3 4 5 | |
Now it only remains to save “ngrams_statistics_sorted” to a file as a “text category profile” or keep just ngrams without occurrences sum when comparing them against others profiles.
Comparing profiles
To categorize a text first we need to load pre-computed categories into a list/dict or something similar and, when loaded, walk it and calculate distance with each previously computed profile:
1 2 3 4 5 6 7 8 9 10 | |
Conclusions
N-Gram-Based text categorization is probably not the “state-of-art” in text categorization - almost ten years old and a bit simple compared with newer ways of categorizing text - but it could be useful in some situations and as a basis to build upon and, what the heck, i learned doing it and had great time, so it totally worth it to me ;)
See you soon!