Introduction
These days i’m messing around with an application that index thousands of documents per day and perform hundreds of queries per hour, so query performance is crucial. The main aim is to provide detection of URLs and IP addresses (want to play a bit? take a look to a previous post) but full-text searching capabilities is also desired althought less used, so i have given a try to improve performance and, specifically, query times, and here is my tests results.
Actually the core’ schema.xml it’s something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
As can be seen, it only indexes and store given text, url and hash (used for avoid dupes), converting case to lower and tokenizing by whitespaces. This means that a document with content “SPAM Visit blog.alejandronolla.com” will be tokenized to “[‘spam’, ‘visit’, ‘blog.alejandronolla.com’]” so, if we want to search documents mentioning any subdomain of alejandronolla.com we would have to search something like “text:*alejandronolla.com” (it could vary based on decisions like looking for domains similar to alejandronolla.com.PHISINGSITE.com or just whatever.alejandronolla.com).
This kind of queries, using leading/trailing wildcars, are really expensive for solr because it can’t use just indexed tokens but perform some walking up to “n” characters more.
Avoiding solr heap space problems
When dealing with a lot of documents concurrently probably you’re going to face heap space problems sooner or later so i strongly recommend to increase RAM asigned to java virtual machine.
In this case i use Tomcat to serve solr, so i needed to modify JAVA_OPTS in catalina.sh (stored at “/usr/share/tomcat7/bin/catalina.sh”):
1 2 3 4 5 | |
Adding “-Xms2048m -Xmx16384m” we specify tomcat to preallocate at least 2048MB and maximum of 16384MB for heap space for avoiding heap space problems (in my tests i almost used about 2GB indexing about 300k documents in two differents cores, so there is plenty of RAM left yet):
Handling thousand of concurrent connections with Tomcat
We have to set some configuration at “/etc/tomcat6/server.xml”:
1 2 3 4 5 | |
I have set up maxThreads to 10000 because i want to index documents through API REST with a python script using async HTTP requests to avoid loosing too much time indexing data (and i’m almost sure bottleneck here is python and not solr).
First improvement: Separate the grain from the chaff
As previously said, most of the queries looks for domains and IP addresses through full document’s content, causing really heavy queries (and performance problems), so the first action i took was to create a new fields just with “domains look’s like” string and IP addresses to tie down queries just to potentially valuable info.
To extract domains, emails and similar strings solr already have a really powerful tokenizer called solr.UAX29URLEmailTokenizerFactory, so we only need to tell solr to index given document text using this tokenizer in another field.
To specify solr which and where field we want to copy we have to create two new fields and specify source and destination fields:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
We are going to use these fields only for searching, so we specify to index but not store (we already have full document content in “text” field) It’s important to have in mind the fact that solr copy fields before doing any kind of processing to document.
If you have noticed it, we specified an undeclared field type called “ip_addresses”, and we are going to use solr.PatternTokenizerFactory to make a regex for extracting IP addresses and CIDR network ranges (like 192.168.1.0/16)
1 2 3 4 5 6 7 8 9 | |
It’s a really simple regex and should be improved before using it in a production environment for example, to extract only certain IP addresses (not RFC1918, not bogus, quad-octet validated, and so on) or even implement your own tokenizer extending existing ones, but will fit ok for our tests.
Now we can change queries from “text:*alejandronolla.com” to “text_UAX29:*alejandronolla.com” to walk much smaller subset of data, improving queries in a huge way.
UPDATE:
I totally forgot to specify to filter out all tokens that are not email or url after tokenizing with UAX29 specification to just store emails and urls. To do this we need to set a token filter at fieldType “text_UAX29”:
1 2 3 4 5 6 | |
In “allowedtypes.txt” file we need to put <EMAIL> and <URL> (one per line) as allowed token type and we should change IP addresses tokenizer to make a small hack and return only IP addresses or extending TokenFilterFactory for filtering after tokenizing process.
Really sorry and apologies for any inconveniences.
Second improvement: Don’t waste resources in features not being used
Solr is a really powerful full-text search engine and, as such, it is able to perform several kind of analysis for indexed data in an automated way. Obviously those analysis need resources to be made so we are wasting CPU cycles and RAM if we are not going to use them.
One of these features is related to solr capability for boosting some query results over others and is based on certain “weight”. For example, two documents mentioning “solr” keyword just one time - one with a length of just few words and the other having several thousands - will have different relevances for solr engine, being more important the smallest one. This is because of term frequency-inverse document frequeny (usually refered as tf-idf) statistic approach, if same keyword appear same number of time it represents a bigger percentage of the entire document in the smallest one.
Because we are not going to use this feature we can disable it and save some resources modifying schema.xml file:
1 2 3 4 5 6 7 8 9 | |
By setting “omitNorms” to “true” we specify solr to not don’t care about length normalization or index-time boosting, you can check the wiki for more information.
Another feature we don’t need now is the solr ability to find similar documents to given one (feature called MoreLikeThis). To do this we can take several approaches as compare tf-idf values or, more accurate way, represent each document as a vector (vector space model) and find near ones (solr mix both).
Because we are not going to use this feature we can set it off by specifying following field options:
1 2 3 4 5 6 7 8 9 | |
I have disabled them with these options ”termVectors=”false” termPositions=”false” termOffsets=”false”” and gain some performance boost.
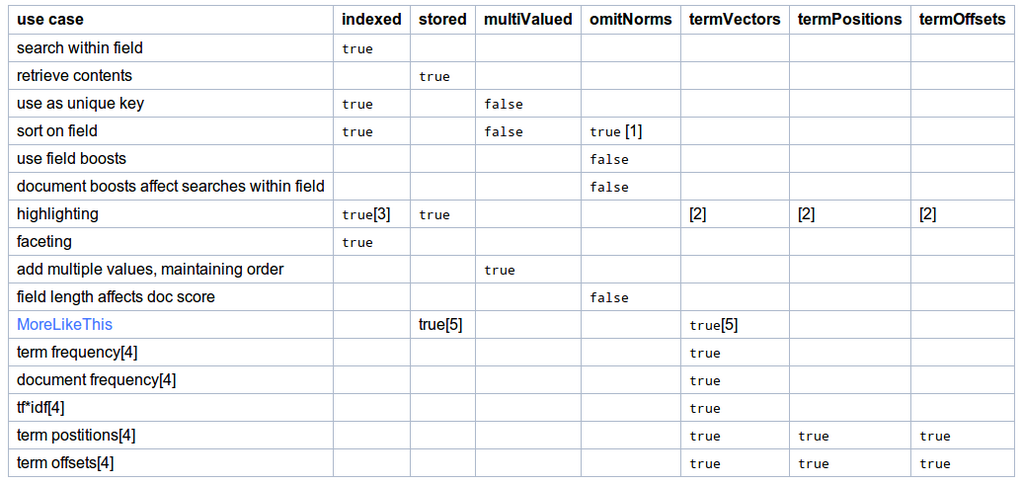
If you want to know which field options to use based on your application aim take a look to official wiki:
Third improvement: Avoid indexing stopwords
When doing natural lenguage processing the term “stopwords” is used to refer those words that should be removed before processing text because of their uselessness. For example, when indexing a document with content like “Visit me at blog.alejandronolla.com” we don’t care about personal pronoun “me” and preposition “at” (take a look to part-of-speech tagging) so less indexed words, less used resources.
To avoid processing those words we need to specify solr where stopwords are located:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
We need to have a file called “stopwords.txt” at our “conf” directory for specified core containing these words and we can find some stopwords for several languages in the example configuration provided with solr package at “/PATH/TO/SOLR/CORE/conf/lang”:
1 2 3 4 5 6 7 8 9 10 11 | |
Of course, we can also include as stop words common words that don’t give us any useful information like dog, bread, ROI, APT and so on…
Fourth impromevent: Word stemming
Despite of haven’t used stemming yet in solr environments it’s possible to convert a given word to his morphological root through an stemming process:
1 2 3 | |
Because we “reduce” words to his root probably few of them, per document, will share stem and this will result in a smaller index and more performance booster.
Fifth improvement: Don’t ask the same two times
Depending on application data and workflow it could be really useful to cache “n” most common queries/filters/documents and avoid doing over and over the same query in a few minutes apart, i’m sorry but haven’t played around too much with it, so to read more about this go to the wiki.
Results
After taking first two improvements actions did some performance test and comparisons, so here are some info for a “small” subset of about 300k documents:
| Original schema | Modified schema | |
| Indexing time: | 95 minutes | 101 minutes |
| Index size: | 555.12 MB | 789.8 MB |
| Field being queried: | text | text_UAX29 |
| Worst query scenario: | 84766 milliseconds | 52417 milliseconds |
| Worst query improvement: | – | 38,2% faster |
As shown in the above table, the “worst” query i’m now performing (dozens of logical operators and wildcards) will take about 38% time less per query hit and, in an application which performs hundreds of query per hour, it’s a great improvement without disrupting normal functioning (looking for domains and IP addresses) and, in the other hand, it will take almost no more time to index and more than reasonable index size increment that worth it.
Hope you liked it and can apply someway to your needs, see you soon!